Processor architecture
The processor service is a Node.js process responsible for data ingestion, transformation and data persisting into the target database. By convention, the processor entry point is at src/main.ts. It is run as
node lib/main.js
For local runs, one normally additionally exports environment variables from .env using dotenv:
node -r dotenv/config lib/main.js
Processor choice
The Squid SDK currently offers specialized processor classes for EVM (EvmBatchProcessor) and Substrate networks (SubstrateBatchProcessor). More networks will be supported in the future. By convention, the processor object is defined at src/processor.ts.
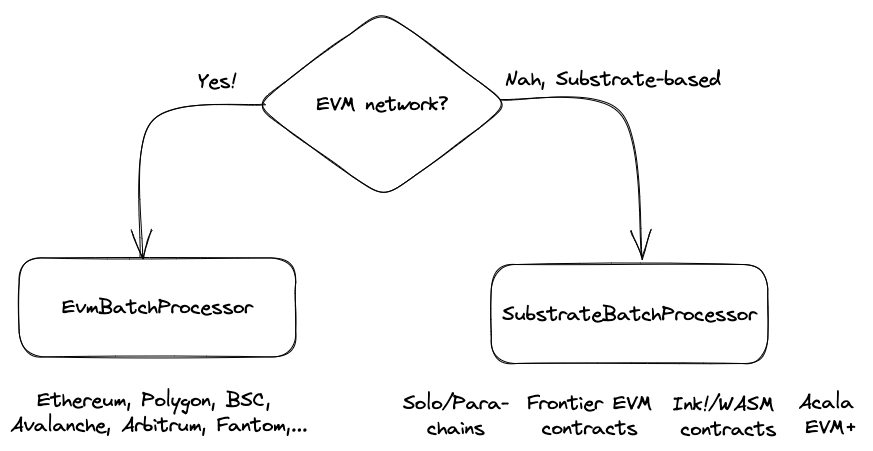
Navigate to a dedicated section for each processor class:
Configuration
A processor instance should be configured to define the block range to be indexed, and the selectors of data to be fetched from SQD Network and/or a node RPC endpoint.
processor.run()
The actual data processing is done by the run() method called on a processor instance (typically at src/main.ts). The method has the following signature:
run<Store>(
db: Database<Store>,
batchHander: (
context: DataHandlerContext<Store, F extends FieldSelection>
) => Promise<void>
): void
The db parameter defines the target data sink, and batchHandler is an async void function defining the data transformation and persistence logic. It repeatedly receives batches of SQD Network data stored in context.blocks, transforms them and persists the results to the target database using the context.store interface (more on context in the next section).
To jump straight to examples, see EVM Processor in action and Substrate Processor in action.
Batch context
Batch handler takes a single argument of DataHandlerContext type:
export interface DataHandlerContext<Store, F extends FieldSelection> {
_chain: Chain
log: Logger
store: Store
blocks: BlockData<F>[]
isHead: boolean
}
Here, F is the type of the argument of the setFields() (EVM, Substrate) processor configuration method. Store type is inferred from the Database instance passed into the run() method.
ctx._chain
Internal handle for direct access to the underlying chain state via RPC calls. Rarely used directly, but rather by the facade access classes generated by the typegen tools.
ctx.log
The native logger handle. See Logging.
ctx.store
Interface for the target data sink. See Persisting data.
ctx.blocks
On-chain data items are grouped into blocks, with each block containing a header and iterables for all supported data item types. Boundary blocks are always included into the ctx.blocks iterable with valid headers, even when they do not contain any requested data. It follows that batch context always contains at least one block.
The set of iterables depends on the processor type (docs for EVM/Substrate). Depending on the data item type, items within the iterables can be canonically ordered by how the data is recorded on-chain (e.g. transactions are ordered but traces are not). The shape of item objects is determined by the processor configuration done via the .setFields() method.
An idiomatic use of the context API is to iterate first over blocks and then over each iterable of each block:
- EVM
- Substrate
processor.run(new TypeormDatabase(), async (ctx) => {
for (let block of ctx.blocks) {
for (let log of block.logs) {
// filter and process logs
}
for (let txn of block.transactions) {
// filter and process transactions
}
for (let stDiff of block.stateDiffs) {
// filter and process state diffs
}
for (let traces of block.traces) {
// filter and process execution traces
}
}
})
processor.run(new TypeormDatabase(), async (ctx) => {
for (let block of ctx.blocks) {
for (let event of block.events) {
// filter and process events
}
for (let call of block.calls) {
// filter and process calls
}
for (let extrinsic of block.extrinsics) {
// filter and process extrinsics
}
}
})
The canonical ordering of ctx.blocks enables efficient in-memory data processing. For example, multiple updates of the same entity can be compressed into a single database transaction.
Please be aware that the processor cannot ensure that data not meeting its filters will be excluded from iterables. It only guarantees the inclusion of data that matches the filters. Therefore, it is necessary to filter the data in the batch handler prior to processing.
ctx.isHead
Is true if the processor has reached the chain head. The last block ctx.blocks is then the current chain tip.